Munin is a popular open source network resource monitoring tool which polls the hosts on your network for statistics for various services, resources and other attributes.
A typical deployment will see Munin being used to monitor CPU usage, memory usage, amount of traffic across network interface, I/O statistics and more – it’s very handy for seeing long term performance trends and for checking the impact that upgrades or adjustments to the environment have made.
Whilst having some overlap with Nagios, Munin isn’t really a replacement, more an addition – I use Nagios to do critical service and resource monitoring and use Munin to graph things in more detail – something that Nagios doesn’t natively do.

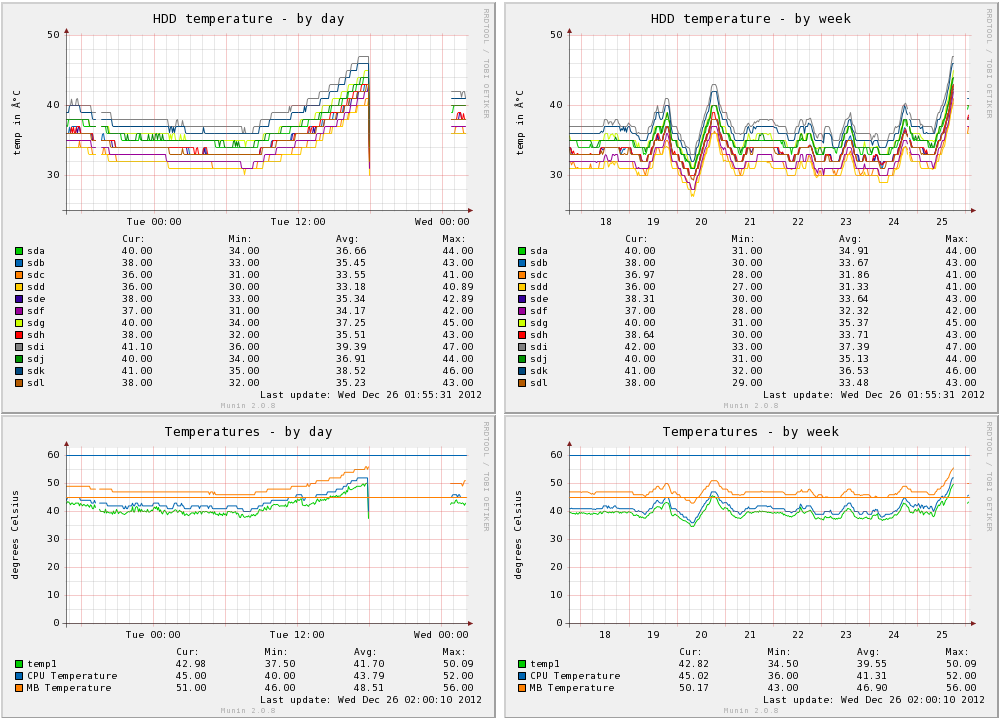
A typical Munin graph - Munin provides daily, weekly, monthly and yearly graphs (RRD powered)
Rather than running as a daemon, the Munin master runs a cronjob every 5minutes that calls a sequence of scripts to poll the configured servers and generate new graphs.
- munin-update to poll configured hosts for new statistics and store the information in RRD databases.
- munin-limits to highlight perceived issues in the web interface and optionally to a file for Nagios integration.
- munin-graph to generate all the graphs for all the services and hosts.
- munin-html to generate the html files for the web interface (which is purely static).
The problem with this model, is that it doesn’t scale particularly well – once you start getting a substantial number of servers, the step-by-step approach can start to run out of resources and time to complete within the 5minute cron period.
For example, the following are the results for the 3 key scripts that run on my (virtualised) Munin VM monitoring 18 hosts:
sh-3.2$ time /usr/share/munin/munin-update
real 3m22.187s
user 0m5.098s
sys 0m0.712s
sh-3.2$ time /usr/share/munin/munin-graph
real 2m5.349s
user 1m27.713s
sys 0m9.388s
sh-3.2$ time /usr/share/munin/munin-html
real 0m36.931s
user 0m11.541s
sys 0m0.679s
It’s a total of around 6 minutes time to run – long enough that the finishing job is going to start clashing with the currently running job.
So why so long?
Firstly, munin-update – munin-update’s time is mostly spent polling the munin-node daemon running on all the monitored systems and then a small amount of I/O time writing the new information to the on-disk RRD files.
The developers have appeared to realise the issue of scale with munin-update and have the ability to run it in a forked mode – however this broke horribly for me with a highly virtualised environment, since sending a poll to 12+ servers all running on the one physical host would cause a sudden load spike and lead to a service poll timeout, with no values being returned at all. :-(
This occurs because by default Munin allows a maximum of 5 seconds for each service query to complete across all hosts and queries all the hosts and services rapidly, ignoring any that fail to respond fast enough. And when querying a large number of servers on one physical host, the server would be too loaded to respond quickly enough.
I ended up boosting the timeouts on some servers to 60 seconds (particular the KVM hosts themselves, as there would sometimes be 60+ LVM volumes that Munin wanted statistics for), but it still wasn’t a good solution and the load spikes would continue.
There are some tweaks that can be used, such as adjusting the max number of forked processes, but it ended up being more reliable and easier to support to just run a single thread and make sure it completed as fast as possible – and taking 3 mins to poll all 18 servers and save to the RRD database is pretty reasonable, particular for a staggered polling session.
After getting munin-update to complete in a reasonable timeframe, I took a look into munin-html and munin-graph – both these processes involve reading the RRD databases off the disk and then writing HTML and RRDTool Graphs (PNG files) to disk for the web interface.
Both processes have the same issue – they chew a solid amount of CPU whilst processing data and then they would get stuck waiting for the disk I/O to catch up when writing the graphs.
The I/O on this server isn’t the fastest at the best of times, considering it’s an AES-256 encrypted RAID 6 volume and the time taken to write around 200MB of changed data each time was a bit too much to do efficiently.
Munin offers some options, including on-demand graph generation using CGIs, however I found this just made the web interface unbearably slow to use – although from chats with the developer, it sounds like version 2.0 will resolve many of these issues.
I needed to fix the performance with the current batch generation model. Just watching the processes in top quickly shows the issue with the scripts, particular with munin-graph which runs 4 concurrent processes, all of them waiting for I/O. (Linux process crash course: S is sleeping (idle), R is running, D is performing I/O operations – or waiting for them).


Clearly this isn’t ideal – I can’t do much about the underlying performance, other than considering putting the monitoring VM onto a different I/O device without encryption, however I then lose all the advantages of having everything on one big LVM pool.
I do however, have plenty of CPU and RAM (Quad Phenom, 16GB RAM) so I decided to boost the VM from 256MB to 1024MB RAM and setup a tmpfs filesystem, which is a in-memory filesystem.
Munin has two main data sources – the RRD databases and the HTML & graph outputs:
# du -hs /var/www/html/munin/
227M /var/www/html/munin/
# du -hs /var/lib/munin/
427M /var/lib/munin/
I decided that putting the RRD databases in /var/lib/munin/ into tmpfs would be a waste of RAM – remember that munin-update is running single-threaded and waiting for results from network polls, meaning that I/O writes are going to be spread out and not particularly intensive.
The other problem with putting the RRD databases into tmpfs, is that a server crash/power down would lose all the data and that then requires some regular processes to copy it to a safe place, etc, etc – not ideal.
However the HTML & graphs are generated fresh each time, so a loss of their data isn’t an issue. I setup a tmpfs filesystem for it in /etc/fstab with plenty of space:
tmpfs /var/www/html/munin tmpfs rw,mode=755,uid=munin,gid=munin,size=300M 0 0
And ran some performance tests:
sh-3.2$ time /usr/share/munin/munin-graph
real 1m37.054s
user 2m49.268s
sys 0m11.307s
sh-3.2$ time /usr/share/munin/munin-html
real 0m11.843s
user 0m10.902s
sys 0m0.288s
That’s a decrease from 161 seconds (2.68mins) to 108 seconds (1.8 mins). It’s a reasonable increase, but the real difference is the massive reduction in load for the server.
For a start, we can see from watching the processes with top that the processor gets worked a bit more to complete the process, since there’s not as much waiting for I/O:

 With the change, munin-graph spends almost all it’s time doing CPU processing, rather than creating I/O load – although there’s the occasional period of I/O as above, I suspect from the time spent reading the RRD databases off the slower disk.
With the change, munin-graph spends almost all it’s time doing CPU processing, rather than creating I/O load – although there’s the occasional period of I/O as above, I suspect from the time spent reading the RRD databases off the slower disk.
Increased bursts of CPU activity is fine – it actually works out to less CPU load, since there’s no need for the CPU to be doing disk encryption and hammering 1 core for a short period of time is fine, there’s plenty of other cores and Linux handles scheduling for resources pretty well.
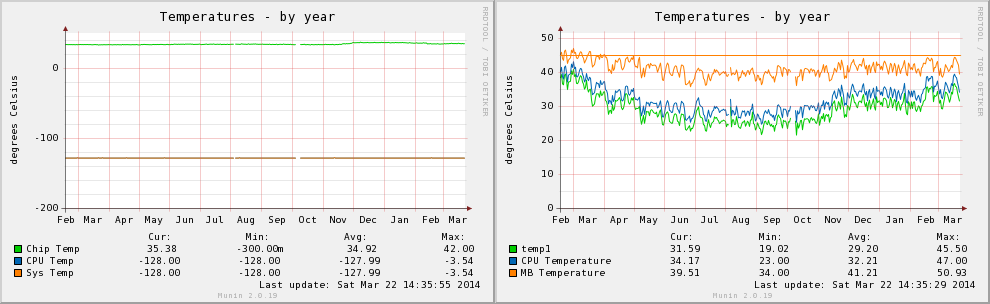
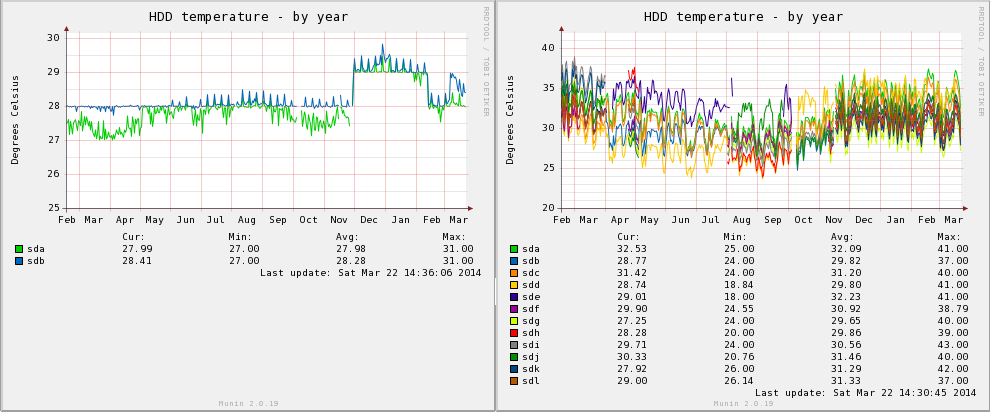
We can really see the difference with Munin’s own graphs for the monitoring VM after making the change:

 In addition, the host server’s load average has dropped significantly, as well as the load time for the web interface on the server being insanely fast, no more waiting for my browser to finish pulling all the graphs down for a page, instead it loads in a flash. Munin itself gives you an idea of the difference:
In addition, the host server’s load average has dropped significantly, as well as the load time for the web interface on the server being insanely fast, no more waiting for my browser to finish pulling all the graphs down for a page, instead it loads in a flash. Munin itself gives you an idea of the difference:

If performance continues to be a problem, there are some other options such as moving RRD databases into memory, patching Munin to do virtualisation-friendly threading for munin-update or looking at better ways to fix CGI on-demand graphing – the tmpfs changes would help a bit to start with.