I’ve been using WordPress for this blog for a number of years now – at some point I realised that whilst writing my own code is fun, there’s no need to reinvent yet-another-fucking-blog-platform and ended up selecting WordPress to use for my content, on the basis of it’s strong and active development and community.
Generally it’s pretty good, but there are times it disappoints, such as WordPress expecting servers to have FTP for unpacking updates and plugins (it’s 2013 guys, SFTP at least!), excessively setting cookies which makes caching layers more complex and doing stupid stuff with storing full URLs inside the database for page links and image resources.
The latter has been impacting me in particular. Visitors to my site have had the option of using HTTP or HTTPS (SSL secured) access methods for some time, but annoyingly whenever I posted an article with images, WordPress includes all the images using http://. This mixed content type prevents browsers from showing the lock icon (best case) or throws up a nasty error (worst case) depending on the browser and it’s level of concern for user safety for mismatched content.
Dubious Firefox is dubious about this site, no lock icon of security here!

Despite having accessed the site on https://, WordPress still uses http:// for my images.
I could work around this by setting the WordPress base URL for my site to be https://www.jethrocarr.com, but then images served at the unsecured http:// site would also be served via SSL, which is just adding pointless load to the server (not that SSL termination really adds much load these days, but damnit, I’m being a purist here!).
I was hoping that it was a misconfiguration of my WordPress setup, but reading online it seems that this is a known issue with WordPress and a whole bunch of modules, hacks and themes have sprung up to fix/workaround the issue…
Of course there’s an easier way – fix it at the webserver layer! Both Nginx and Apache have modules to do substitutions in page content on load, for Nginx there’s HttpSubModule and for Apache there is mod_substitute. In my case with stock Apache 2.2 on CentOS 5, I was able to fix the whole issue by adding the following to my SSL vhost configuration:
# Fix SSL URLs thanks to WordPress hardcoding http:// links to images :'( <Location /> AddOutputFilterByType SUBSTITUTE text/html Substitute "s|http://www.example.com|https://www.example.com|" </Location>
Following this, things look much better:
The lock icon of browser approval!
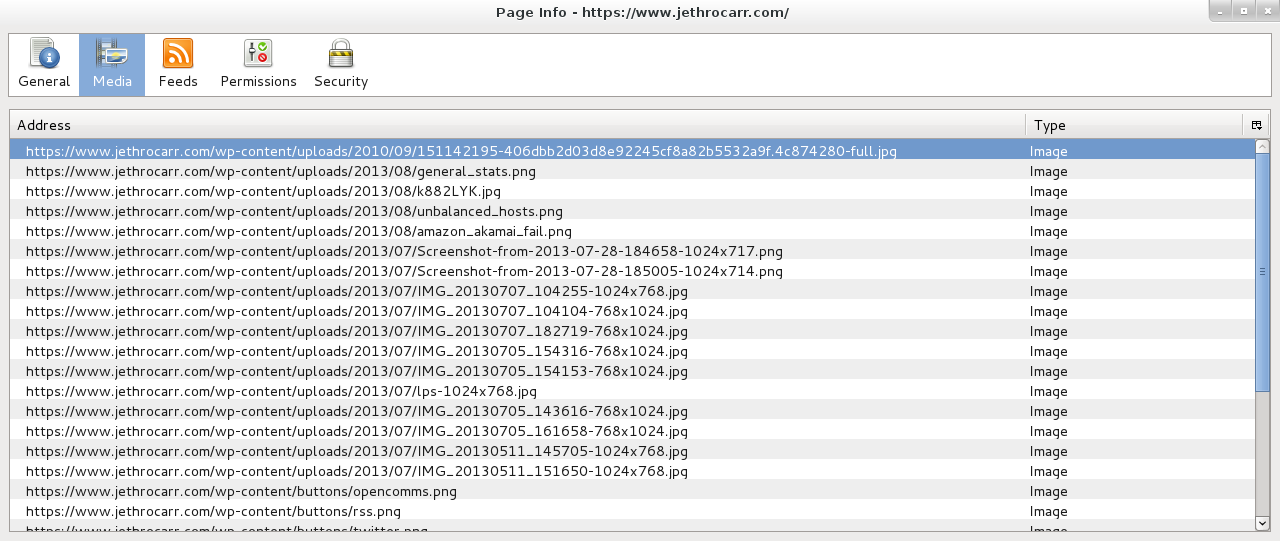
All media files are now https://, not http://
Technically this substitution will have some level of performance impact, as it has to process the generated HTML content and check for strings to replace, but the impact is so low that I wasn’t able to measure it amongst the usual variation of page response times – and it’s not going to be anywhere as slow as mod_php and WordPress itself anyway. ;-)
Finally, if you haven’t already, you probably want to change the following in wp-config.php:
define('FORCE_SSL_ADMIN', true);
This forces all WordPress logins and wp-admin activities to take place under HTTPS which is a pretty good idea if you ever post to your blog from an unsecured network.