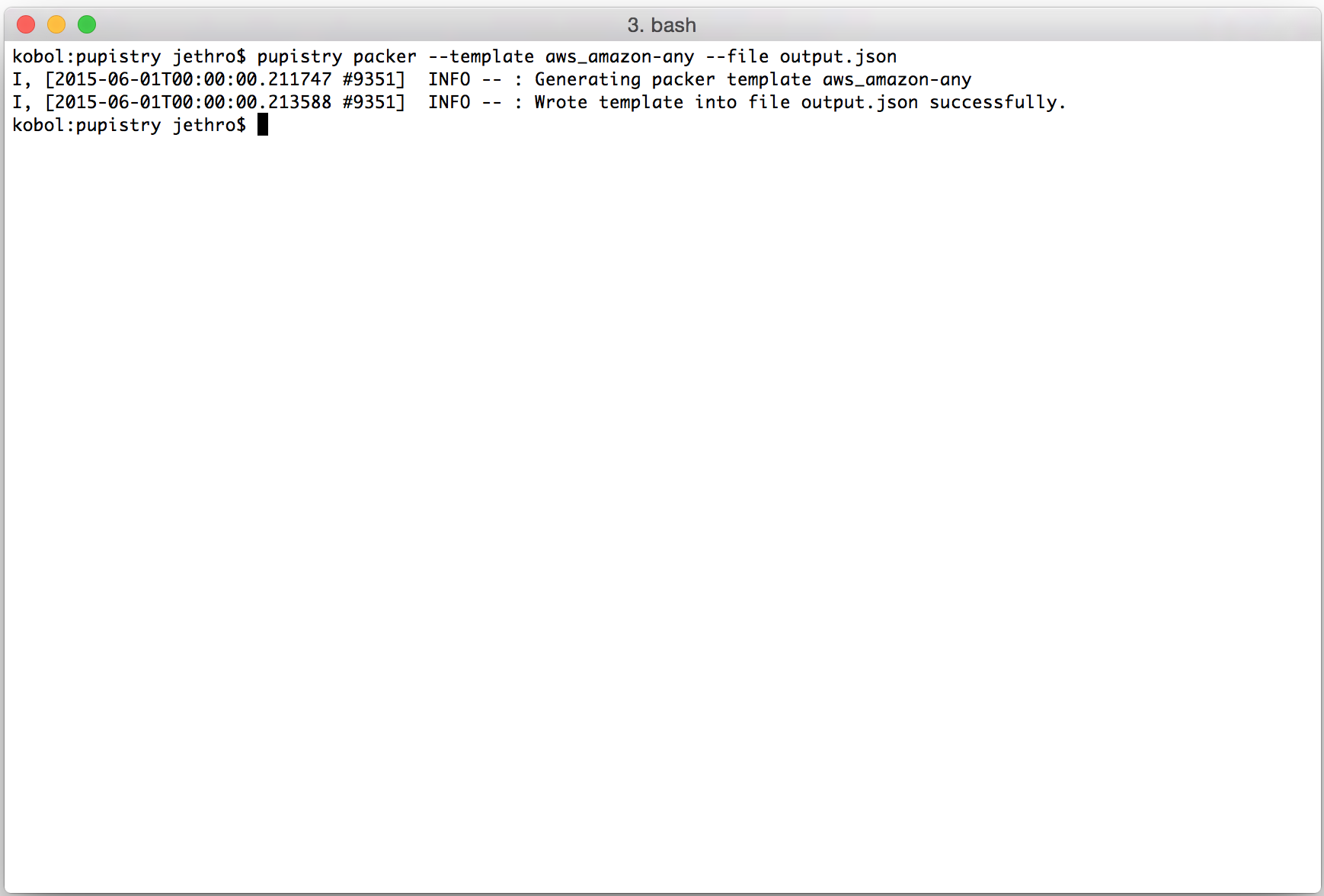
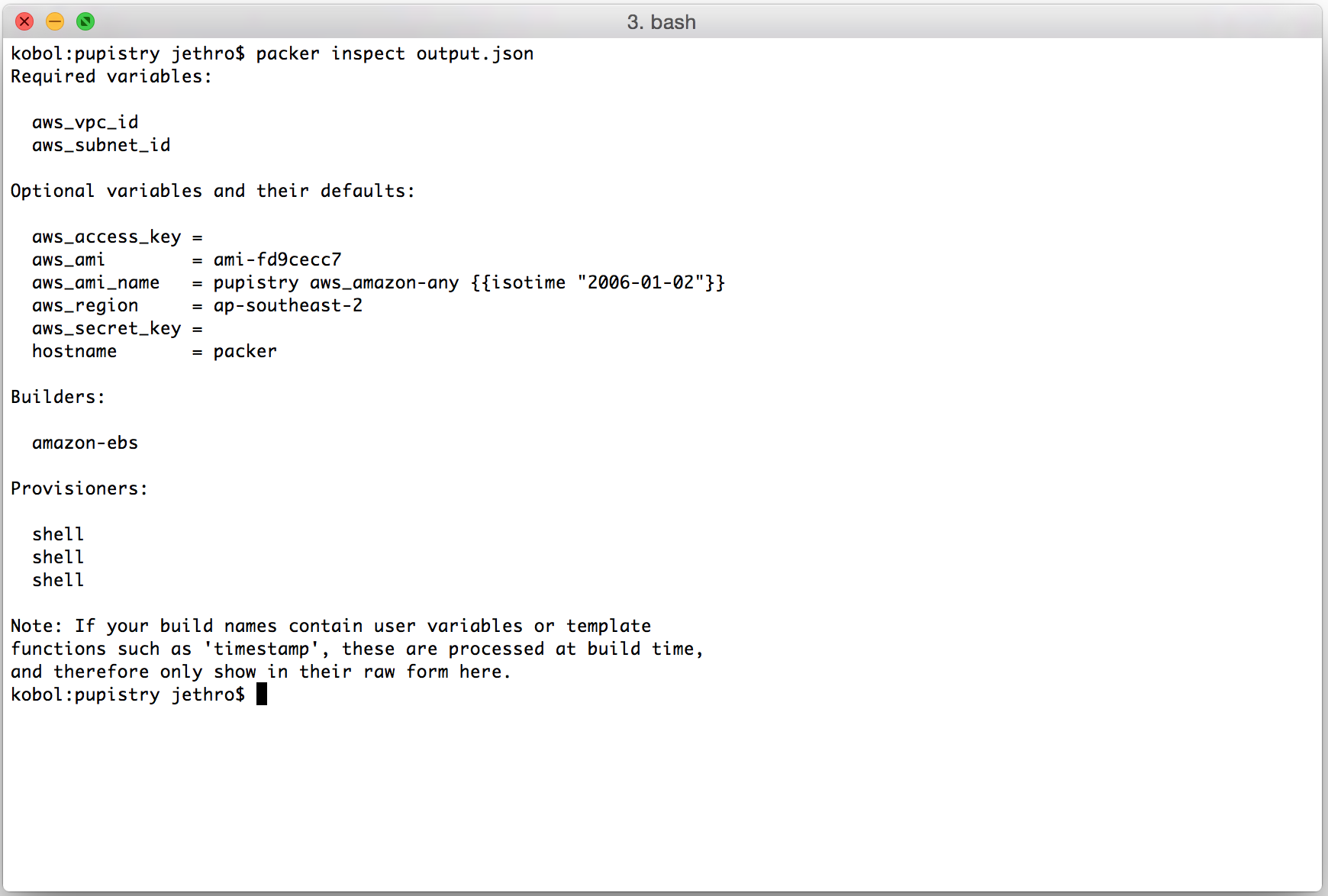
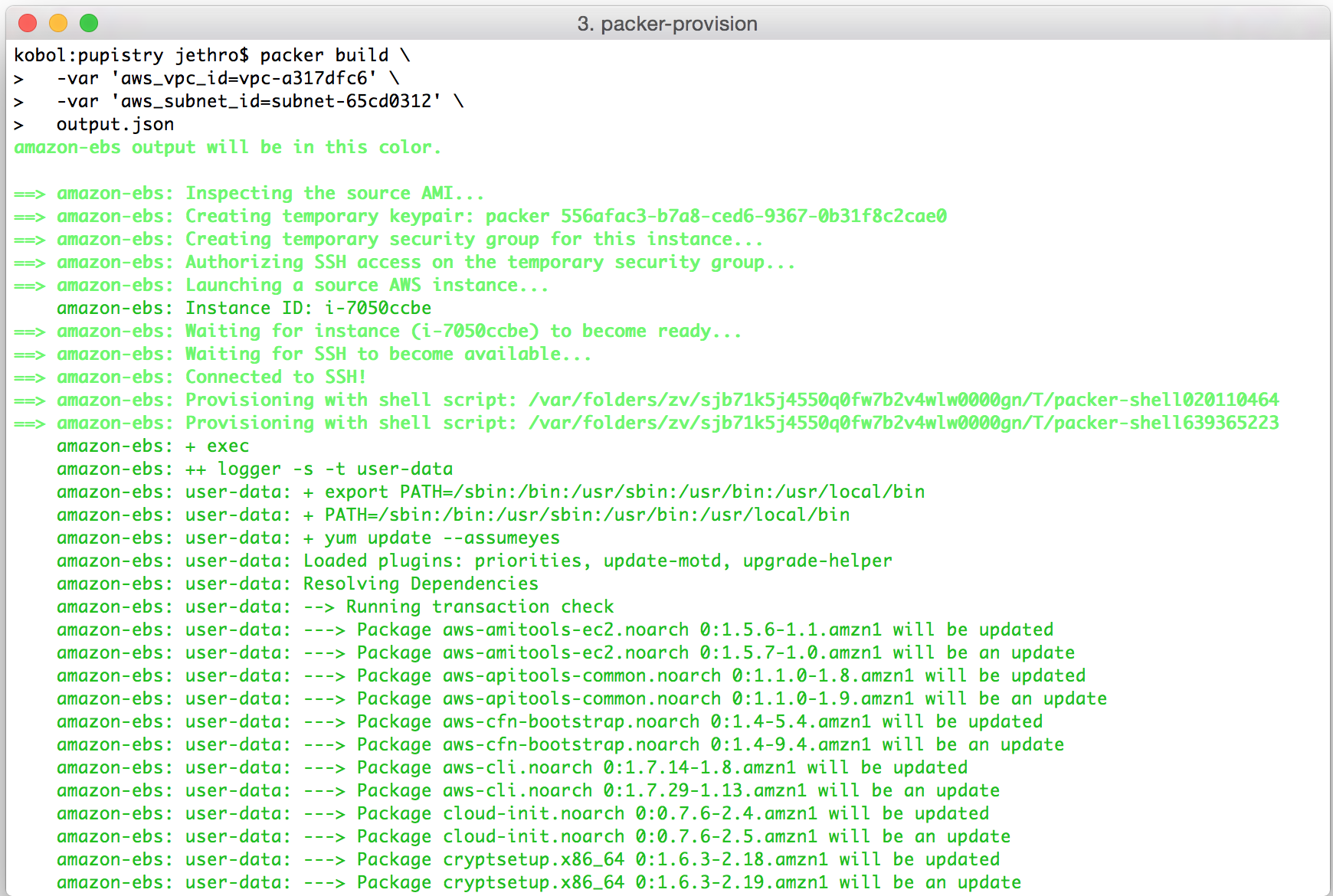
I’m in the middle of doing a migration of my personal server infrastructure from a 2006-era colocation server onto modern cloud hosting providers.
As part of this migration, I’m rebuilding everything properly using Puppet (use it heavily at work so it’s a good fit here) with the intention of being able to complete server builds without requiring any manual effort.
Along the way I’m finding gaps where the available modules don’t quite cut it or nobody seems to have done it before, so I’ve been writing a few modules and putting them up on GitHub for others to benefit/suffer from.
puppet-hostname
https://github.com/jethrocarr/puppet-hostname
Trying to do anything consistently with host naming is always fun, since every organisation or individual has their own special naming scheme and approach to dealing with the issue of naming things.
I decided to take a different approach. Essentially every cloud provider will give you a source of information that could be used to name your instance whether it’s the AWS Instance ID, or a VPS provider passing through the name you gave the machine at creation. Given I want to treat my instances like cattle, an automatic soulless generated name is perfect!
Where they fall down, is that they don’t tend to setup the FQDN properly. I’ve seen a number of solution to this including user data setup scripts, but I’m trying to avoid putting anything in user data that isn’t 100% critical and sticking to my Pupistry bootstrap so I wanted to set my FQDN via Puppet itself.
(It’s even possible to set the hostname itself if desired, you can use logic such as tags or other values passed in as facts to define what role a machine has and then generate/set a hostname entirely within Puppet).
Hence puppet-hostname provides a handy way to easily set FQDN (optionally including the hostname itself) and then trigger reloads on name-dependent services such as syslog.
None of this is revolutionary, but it’s nice getting it into a proper structure instead of relying on yet-another-bunch-of-userdata that’s specific to my systems. The next step is to look into having it execute functions to do DNS changes on providers like Route53 so there’s no longer any need for user data scripts being run to set DNS records at startup.
puppet-rirs
https://github.com/jethrocarr/puppet-rirs
There are various parts of my website that I want to be publicly reachable, such as the WordPress login/admin sections, but at the same time I also don’t want them accessible by any muppet with a bot to try and break their way in.
I could put up a portal of some kind, but this then breaks stuff like apps that want to talk with those endpoints since they can’t handle the authentication steps. What I can do, is setup a GeoIP rule that restricts access to the sections to the countries I’m actually in, which is generally just NZ or AU, to dramatically reduce the amount of noise and attempts people send my way, especially given most of the attacks come from more questionable countries or service providers.
I started doing this with mod_geoip2, but it’s honestly a buggy POS and it really doesn’t work properly if you have both IPv4 and IPv6 connections (one or another is OK). Plus it doesn’t help me for applications that support IP ACLs, but don’t offer a specific GeoIP plugin.
So instead of using GeoIP, I’ve written a custom Puppet function that pulls down the IP assignment lists from the various Regional Internet Registries and generate IP/CIDR lists for both IPv4 and IPv6 on a per-country basis.
I then use those lists to populate configurations like Apache, but it’s also quite possible to use it for other purposes such as iptables firewalling since the generated lists can be turned into Puppet resources. To keep performance sane, I cache the processed output for 24 hours and merge any continuous assignment blocks.
Basically, it’s GeoIP for Puppet with support for anything Puppet can configure. :-)
puppet-digitalocean
https://github.com/jethrocarr/puppet-digitalocean
Provides a fact which exposes details from the Digital Ocean instance API about the instance – similar to how you get values automatically about Amazon EC2 systems.
puppet-initfact
https://github.com/jethrocarr/puppet-initfact
The great thing about the open source world is how we can never agree so we end up with a proliferation of tools doing the same job. Even init systems are not immune, with anything tha intends to run on the major Linux distributions needing to support systemd, Upstart and SysVinit at least for the next few years.
Unfortunately the way that I see most Puppet module authors “deal” with this is that they simply write an init config/file that suits their distribution of choice and conveniently forget the other distributions. The number of times I’ve come across Puppet modules that claim support for Red Hat and Amazon Linux but only ship an Upstart file…. >:-(
Part of the issue is that it’s a pain to even figure out what distribution should be using what type of init configuration. So to solve this, I’ve written a custom Fact called “initsystem” which exposes the primary/best init system on the specific system it’s running on.
It operates in two modes – there is a curated list for specific known systems and then fallback to automatic detection where we don’t have a specific curated result handy.
It supports (or should) all major Linux distributions & derivatives plus FreeBSD and MacOS. Pull requests for others welcome, could do with more BSD support plus maybe even support for Windows if you’re feeling brave.
puppet-yas3fs
https://github.com/pcfens/puppet-yas3fs/commit/27af462f1ce2fe0610012a508236062e65017b5f
Not my module, but I recently submitted a PR to it (subsequently merged) which introduces support for a number of different distributions via use of my initfact module so it should now run on most distributions rather than just Ubuntu.
If you’re not familiar with yas3fs, it’s a FUSE driver that turns S3+SNS+SQS into a shared filesystem between multiple servers. Ideal for dealing with legacy applications that demand state on disk, but don’t require high I/O performance, I’m in the process of doing a proof-of-concept with it and it looks like it should work OK for low activity sites such as WordPress, although with no locking I’d advise against putting MySQL on it anytime soon :-)
These modules can all be found on GitHub, as well as the Puppet Forge. Hopefully someone other than myself finds them useful. :-)