In my day job, I look after a number of websites, all of which generally make heavy use of CDNs (Content Distribution Networks) to offload traffic to edge nodes near to an end user’s device. In our case we use Akamai, one of the largest and experienced providers in the world.
A large number of our clusters and applications now run on Amazon’s public cloud service here in Sydney, making use of EC2 instances and ELBs. Due to the important nature of our systems, we have almost all applications in active-active multi-AZ (Availability Zone) configurations. The intention of this design is that the ELB (Elastic Load Balancer) serves all incoming traffic by dividing it across each availability zone in equal proportions. If either Amazon AZ fails, the other will continue to serve requests like nothing is wrong.
It’s a nicer solution than the traditional data center approach of having an active-passive multi-site design, as with both AZs being constantly active serving requests, we know that production and “DR” are always in a functional working state, ready to handle traffic; plus your investment into DR isn’t going to waste like traditional servers sitting idle.
Unfortunately Amazon ELBs offer only the barest of no-frills features which makes them a bit stupid at times. In particular, Amazon’s multi-AZ ELBs actually consist two separate ELBs, once in each AZ. Incoming traffic selects an ELB by means of a DNS round robin and then is directed to a server in that particular AZ .
Thus, each availability zone has it’s own ELB, which adds it’s own IP address to the DNS round robin, and looks something like this:
www.example.com is an alias for www-example-com-elb.jws.elb.amazonaws.com. www-example-com-elb.jws.elb.amazonaws.com. has address 172.16.32.1 www-example-com-elb.jws.elb.amazonaws.com. has address 192.168.0.1
The problem is that DNS round robin has no guarantee of balancing the load evenly across the two data centers. If a particular company’s proxy server caches one address, it may direct traffic for the whole company to AZ-A and deliver no traffic to AZ-B.
In reality, due to the large number of users getting assigned different IP addresses with round robin, users tend to be spread somewhat evenly across the different AZs, making the problem a somewhat moot point when you have sizeable visitor numbers.
But if you add Akamai to the mix, you can end up with interesting results – it turns out that Akamai Edge nodes in AU use a central source of DNS information, which can lead to them favouring a particular ELB IP address. And since *all* your traffic goes via the CDN, this in turn results in all your traffic going directly to a single AZ and ignoring the other one entirely.
In a real-world scenario of a 4 webserver cluster, we saw traffic jump between each AZ whenever Akamai’s edge servers updated DNS to a different IP address, as per the below graph:
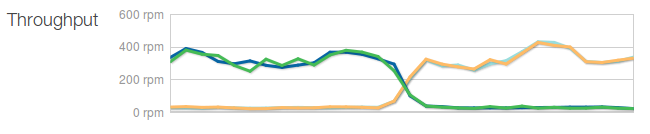
Akamai decides to switch which ELB it’s using from A to B :-/
This swapping brings around some really nasty issues. In theory your active-active setup should be large enough to handle all your usual traffic load on just one AZ, but if that’s not the case, bad things will happen to your site performance and/or reliability.
The other nasty issue is when doing auto-scaling with Amazon, this swapping messes with your Cloud Watch metrics for autoscale policies/triggers – one AZ is complete idle, one AZ is maxed out, average stats show a half busy cluster, no need to autoscale upwards to handle the load.
And even if you’re clever and set your autoscaling to also trigger based on ELB latency/errors/throughput, you may still end up with issues, since the new host created during the autoscale may end up in the idle AZ, instead of the active AZ where you need it.
Using a smarter system for load balancing can negate the issue – for example using a pair of Varnish servers or HA-Proxy servers configured to do cross-AZ load balancing would workaround the issue, by spreading all the traffic coming into one AZ across all the servers in both AZs, but this does have increased costs (running EC2 instances, inter-AZ traffic). It also may have performance issues depending on the amount of traffic pouring into your instance.
Additionally, if you have a global audience, rather than a mostly single-country audience like us, you may not see the issue, since the different Akamai regions around the world will balance load somewhat equally across the two AZs.
To properly fix this behaviour with Akamai, you need to open a professional services request and have the SureRoute configuration adjusted so that Akamai forces the edge notes to lookup the origin IPs at the edge:
<!-- SR fix to handle multiple origin IP's --> <forward:cache-parent.sureroute2.force-origin-ip-from-edge>on </forward:cache-parent.sureroute2.force-origin-ip-from-edge> <forward:cache-parent.sureroute2.round-robin.status>on </forward:cache-parent.sureroute2.round-robin.status> <!-- no host in sureroute stat-key --> <forward:cache-parent.sureroute2.stat-key.host>off </forward:cache-parent.sureroute2.stat-key.host>
With this fixed configuration, Akamai will correctly spread load evenly across our two AZs and our load graphs settled comfortably back into normality. I’m not entirely sure why this configuration isn’t default SureRoute behaviour, but like many things with Akamai, there are often mysterious adjustments that only professional services know about or can make.
Finally it’s worth noting that this issue isn’t unique to Amazon – you could get the same issue if you run active-active conventional data centers and use Akamai for offload. It may also be an issue with other CDNs by default, so double-check the behaviour of your particular vendor – it would be interesting to see if CloudFront (Amazon’s CDN) exhibits similar issues or not.
Credit to my colleague Andrew. for spotting this issue originally and having to deal with two different vendors support cases at once to get to the bottom of the root cause.
Cool
http://aws.amazon.com/about-aws/whats-new/2013/11/06/elastic-load-balancing-adds-cross-zone-load-balancing/
Amazon has just announced improvements to ELBs which will allow cross AZ-load balancing. This should provide a fix for this behaviour, but it has to be specifically enabled.