RAID is designed to handle the loss of hard disks due to hardware failure and can ensure continual service during such a time. But hard drives are wonderful creatures and instead of dying quickly, they can often prolong their death with bad sectors, slow performance or other nasty issues.
In a RAID array if a disk fails in a clear defined fashion, the RAID array will mark it as failed and move on with it’s life. But if the disk is still functioning at reduced performance, write operations on the array will be slowed down to the speed of the slowest disk, as the write doesn’t return as complete until all disks have completed their operation.
It can be tricky to see gradual performance decreases in I/O performance until it reaches a truly terrible level of performance that it can’t go unnoticed due to impacting services in a clear and obvious fashion.
Thankfully tools like Munin make it much easier to see degrading performance over time. I was recently having I/O performance issues thanks to a failing disk and using Munin was quickly able to see which disk was responsible, as well as seeing the level of impact it was making on my system’s performance.
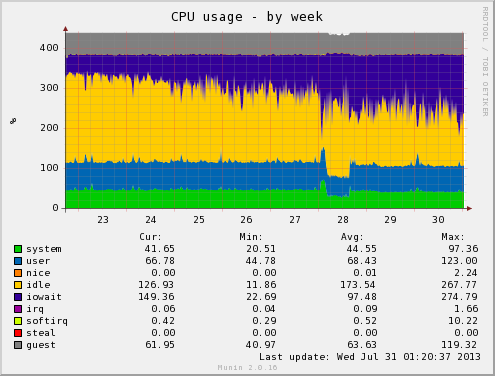
Wasting almost 2 cores of CPU due to slow I/O holding up processes.
The CPU usage graph is actually very useful for checking out storage related problems, since it records the time spent with the CPU in an idle state due to waiting for storage to catch up and provide data required for operations.
This alone isn’t indicative of a fault – you could get similar results if you are loading your system with too many I/O intensive tasks and your storage just isn’t fast enough for your needs (Are hard disks ever fast enough?), plus disk encryption always imposed some noticeable amount of I/O wait; but it’s a good first place to look.
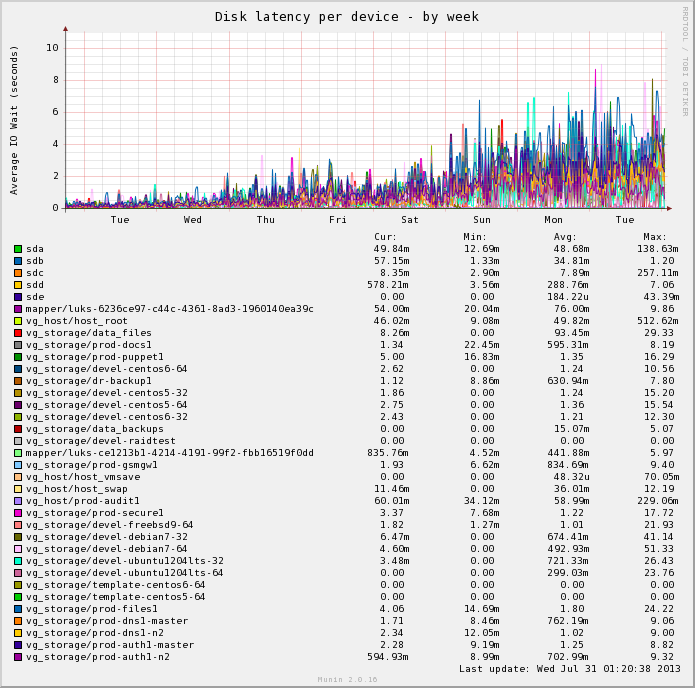
All the disks!
The disk latency graph is also extremely valuable and quickly shows the disk responsible. My particular example isn’t idle, since Munin has decided to pickup all my LVM volumes and include them on the graphs which makes it very unreadable.
Looking at the stats it’s easy to see that /dev/sdd is suffering, with an average latency of 288ms and a max peak of 7.06 *seconds*. Marking this disk as failed in the array instantly restored performance and I was then able to replace the disk and rebuild the array, restoring expected performance.
Note that this RAID array is built with consumer grade SATA disks, which are particularly bad for this kind of issue – an enterprise grade SATA disk would have been more likely to fail faster and more definitively, as they are designed primarily for RAID environments where the health of the array is more important than one disk doing everything possible to keep itself going.
In my case I’m using software RAID which makes it easy to see the statistics of each disk, since the controller is acting in a JBOD mode and exposing the disks directly to the OS. Using consumer disks like these could be much more “interesting” with a hardware RAID controller that wouldn’t expose the same amount of information… if using a hardware RAID controller, I’d advise to shell up the cash and use enterprise grade disks designed for RAID arrays or you could have a much more difficult life.
Very impressive Jethro. Great write up on RAID performance and the failure of hard drives. Very useful tool you offer as a resource. You definitely know your stuff. IF you ever need data recovery or know anyone that needs RAID recovery please contact us at my email in your admin. I don’t want to highjack your post here for advertisement purposes. :) Great content