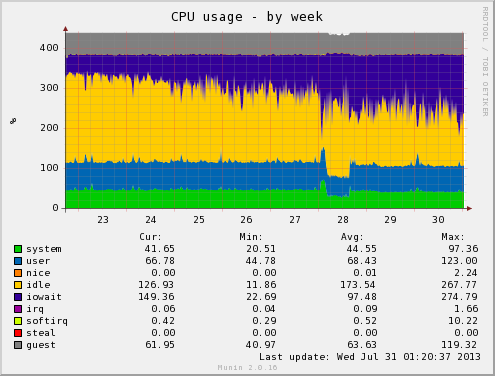
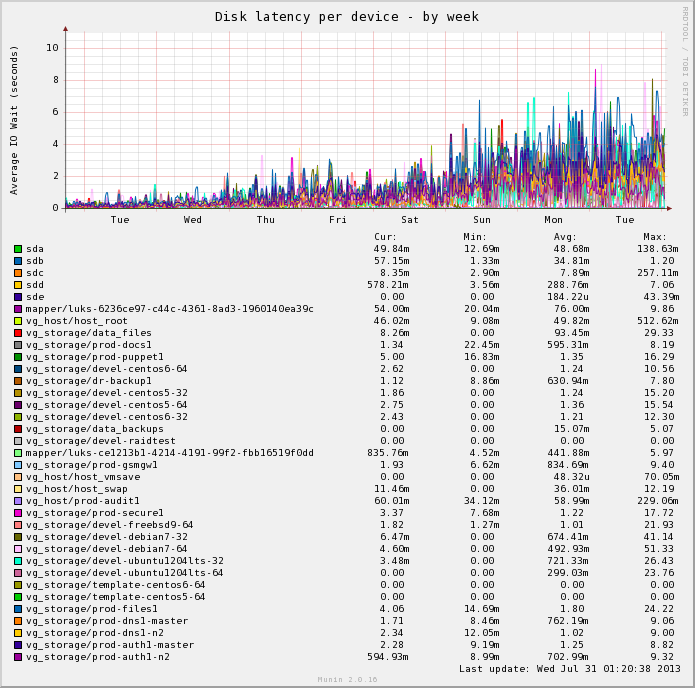
I recently wrote about bad hard disks being responsible for impacting array performance negatively after having some consumer grade disks fail in a fashion that impacted performance, but didn’t result in the disk being marked as bad.
I recently wrote about bad hard disks being responsible for impacting array performance negatively after having some consumer grade disks fail in a fashion that impacted performance, but didn’t result in the disk being marked as bad.
Since then I’ve been doing more research into the differences between consumer and enterprise disks after noting that consumer SATA disks appear to be more susceptible to this sort of performance degrading failure behaviour than enterprise disks which fail cleaner/faster, but also have a much higher purchase cost.
Consumer disks are built with the exception that they’ll be running standalone in a desktop computer where spending a few seconds remapping some bad sectors or running healing procedures is better than data loss. But this messes with the performance when in RAID arrays and leads to drives with poor latency or drives that try to keep correcting and hiding failing sectors from the array controller.
Enterprise SATA disks are mostly the same from a hardware perspective, however they have a different firmware load designed with the assumption that the disk is part of a RAID array. If an enterprise disk has a failure, it should die quickly and cleanly so that the RAID array can then handle the process of repairing – after all, the array has parity information and can rebuild a new disk, it doesn’t need a failing disk to try and rescue itself.
I did some digging on the technical differences between enterprise and consumer disks – the information can be tricky to find with so many people making blind recommendations for either option based on anecdotal evidence and hearsay – but I did manage to dig up some useful articles on the subject:
- White paper by Intel on consumer vs enterprise drives [PDF], probably one of the best summaries of the differences that I’ve read.
- Comparison by Synology of Consumer vs Enterprise grade disks.
- NetApp talking about the differences in enterprise vs consumer disks.
- The wikipedia article on TLER details how having time outs on enterprise disks can make them fail fast and how consumer disks that lack the feature can get marked as bad more frequently by RAID controllers.
When I built my file server a couple years ago, I purchased 8x standard consumer grade Seagate 7200.12 disks and 2x enterprise grade Seagate ES disks as a small test to see if the enterprise drives prove themselves more reliable than the general consumer grade disks.
Since doing this, I’ve had a few disks fail, including one enterprise grade disk. The only noticeable difference I’ve found is that the enterprise disk died much more cleanly, failing completely, whereas the consumer disks lingered on a bit longer messing things up with weird latency issues, or failed sectors that subsequently re-mapped.
Personally I’ll continue to use consumer grade disks for my systems – I keep a pretty close eye on my system so can manually toss any badly performing consumer disks out of the array and I’m also using Linux MD software RAID which is much more tolerant of sluggish consumer grade disks than a hardware RAID controller. Additionally, Linux software RAID is far easier to manage and just as fast as a budget level hardware RAID controller.
However if working with a business server with a high quality RAID controller with onboard battery-backed memory cache, I would certainly spend the extra few dollars for enterprise grade disks. Not only for the RAID advantages, but also because having the enterprise grade disks fail quick and obviously will make them more cost effective long term by reducing the amount of time that employees spend debugging poorly performing systems.