Given the amount of internet connected things I now rely on at home, I’ve been considering redundant internet links for a while. And thanks to the affordability of 3G/4G connectivity, it’s easier than ever to have a completely diverse carrier at extremely low cost.
I’m using 2degrees which has a data SIM sharing service that allows me to have up to 5 other devices sharing the one data plan, so it literally costs me nothing to have the additional connection available 24×7.
My requirements were to:
- Handle the loss of the wired internet connection.
- Ensure that I can always VPN into the house network.
- Ensure that the security cameras can always upload footage to AWS S3.
- Ensure that the IoT house alarm can always dispatch events and alerts.
I ended up building three distinct components to build a failover solution that supports flipping between my wired (VDSL) and wireless (3G) connection:
- A small embedded GNU/Linux system that can bridge a USB 3G modem and an ethernet connection, with smarts to recover from various faults (like crashed 3G stick).
- A dynamic DNS solution, since my mobile telco certainly isn’t going to give me a static IP address, but I need inbound traffic.
- A DNS failover solution so I can redirect inbound requests (eg home VPN) to the currently active endpoint automatically when a failure has occurred.
The Hardware
I considered using a Mikrotik with USB for the 3G link – it is a supported feature, but I decided to avoid this route since I would need to replace my perfectly fine router for one with a USB port, plus I know from experience that USB 3G modems are fickle beasts that would be likely to need some scripting to workaround various issues.
For the same reason I excluded some 3G/4G router products available that take a USB modem and then provide ethernet or WiFi. I’m very dubious about how fault tolerant these products are (or how secure if consumer routers are anything to go by).
I started off the project using a very old embedded GNU/Linux board and 3G USB modem I had in the spare parts box, but unfortunately whilst I did eventually recycle this hardware into a working setup, the old embedded hardware had a very poor USB controller and was throttling my 3G connection to around 512kbps. :-(

Initial approach – Not a bomb, actually an ancient Gumstix Verdex with 3G modem.
So I started again, this time using the very popular Raspberry Pi 2B hardware as the base for my setup. This is actually the first time I’ve played with a Raspberry Pi and I actually really enjoyed the experience.
The requirements for the router are extremely low – move packets between two interfaces, dial a modem and run some scripts. It actually feels wasteful using a whole Raspberry Pi with it’s whole 1GB of RAM and Quad Core ARM CPU, but they’re so accessible and cost affordable, it’s not worth the time messing around with any more obscure embedded boards.

Pie ingredients
It took me all of 5 mins to assemble and boot an OS on this thing and have a full Debian install ready for work. For this speed and convenience I’ll happily pay a small price premium for the Raspberry Pi than some other random embedded vendors with much more painful install and upgrade processes.

Baked!
It’s important to get a good power supply – 3G/4G modems tend to consume the full 500mW available to them. I kept getting under voltage warnings (the red light on the Pi turns off) with a 2.1 Amp phone charger I was using. Ended up buying the official 2.5 Amp Raspberry Pi charger, which powers the Raspberry Pi 2 + the 3G modem perfectly.
I brought the smallest (& cheapest) class 10 Micro SDHC card possible – 16GB. Of course this is way more than you actually need for a router, 4GB would have been plenty.
The ZTE MF180 USB 3G modem I used is a tricky beast on Linux, thanks to the kernel seeing it as a SCSI CDROM drive initially which masks the USB modem features. Whilst Linux has usb_modeswitch shipping as standard these days, I decided to completely disable the SCSI CDROM feature as per this blog post to avoid the issue entirely.
The Software
The Raspberry Pi I was given (thanks Calcinite! ?) had a faulty GPU so the HDMI didn’t work. Fortunately Raspberry Pi doesn’t let such a small issue like no display hold it back – it’s trivial to flash an image to the SD card from another machine and boot a headless installation.
- Download Raspbian minimal/lite (Debian + Raspberry Pi goodness).
- Installed image to the SD card using the very awesome Etcher.io (think “safe dd” for noobs) as per the install instructions using my iMac.
- Enable SSH as per instructions: “SSH can be enabled by placing a file named
ssh, without any extension, onto the boot partition of the SD card. When the Pi boots, it looks for thesshfile. If it is found, SSH is enabled, and the file is deleted. The content of the file does not matter: it could contain text, or nothing at all.” - Login with username “pi” and password “raspberry”.
- Change the password immediately before you put it online!
- Upgrade the Pi and enable automated updates in future with:
apt-get update && apt-get -y upgrade apt-get install -y unattended-upgrades
The rest is somewhat specific to your setup, but my process was roughly:
- Install apps needed – wvdial for establishing the 3G connection via AT commands + PPP, iptables-persistent for firewalling, libusb-dev for building hub-ctrl and jq for parsing JSON responses.
apt-get install -y wvdial iptables-persistent libusb-dev jq
- Configure a firewall. This is very specific to your network, but you’ll want both ipv4 and ipv6 rules in /etc/iptables/rules.* Generally you’d want something like:
- Masquerade (NAT) traffic going out of the ppp+ and eth0 interfaces.
- Permit forwarding traffic between the interfaces.
- Permit traffic in on port 9000 for the health check server.
- Enable IP forwarding (net.ipv4.ip_forward=1) in /etc/sysctl.conf.
- Build hub-ctrl. This utility allows the power cycling of the USB controller + attached devices in the Raspberry Pi, which is extremely useful if your 3G modem has terrible firmware (like mine) and sometimes crashes hard.
wget https://raw.githubusercontent.com/codazoda/hub-ctrl.c/master/hub-ctrl.c gcc -o hub-ctrl hub-ctrl.c -lusb
- Build pinghttpserver. This is a tiny C-based webserver which we can use to check if the Raspberry Pi is up (Can’t use ICMP as detailed further on).
wget -O pinghttpserver.c https://gist.githubusercontent.com/jethrocarr/c56cecbf111af8c29791f89a2c30b978/raw/9c53f66fbed609d09652b8c4ceff0194876c05a3/gistfile1.txt make pinghttpserver
- Configure /etc/wvdial.conf. This will vary by the type of 3G/4G modem and also the ISP in use. One key value is the APN that you use. In my case, I had to set it to “direct” to ensure I got a real public IP address with no firewalling, instead of getting a CGNAT IP, or a public IP with inbound firewalling enabled. This will vary by carrier!
[Dialer Defaults] Init1 = ATZ Init2 = ATQ0 V1 E1 S0=0 &C1 &D2 +FCLASS=0 Init3 = AT+CGDCONT=1,"IP","direct" Stupid Mode = 1 Modem Type = Analog Modem Phone = *99# Modem = /dev/ttyUSB2 Username = { } Password = { } New PPPD = yes - Edit /etc/ppp/peers/wvdial to enable “defaultroute” and “replacedefaultroute” – we want the wireless connection to always be the default gateway when connected!
- Create a launcher script and (once tested) call it from /etc/rc.local at boot. This will start up the 3G connection at boot and launch various processes we need. (this could be nicer and be a collection of systemd services, but damnit I was lazy ok?). It also handles reboots and powercycling USB if problems are encountered for (an attempt) at automated recovery.
wget -O 3g_failover_launcher.sh https://gist.githubusercontent.com/jethrocarr/a5dae9fe8523cf74d30a065d77d74876/raw/57b5860a9b3f6a048b02b245f3628ee60ea766dc/3g_failover_launcher.sh
At this point, you should be left with a Raspberry Pi that gets a DHCP lease on it’s eth0, dials up a connection with your wireless telco and routes all traffic it receives on eth0 to the ppp interface.
In my case, I setup my Mikrotik router to have a default GW route to the Raspberry Pi and the ability to failover based on distance weightings. If the wired connection drops, the Mikrotik will shovel packets at the Raspberry Pi, which will happily NAT them to the internet.
The DNS Failover
The work above got me an outbound failover solution, but it’s no good for inbound traffic without a failover DNS record that flips between the wired and wireless connections for the VPN to target.
Because the wireless link would be getting a dynamic IP addresses, the first requirement was a dynamic DNS service. There are various companies around offering free or commercial products for this, but I chose to use a solution built around AWS Lambda that can be granted access directly to my DNS hosted inside Route53.
AWS have a nice reference dynamic DNS solution available here that I ended up using (Sadly not using the Serverless framework so there’s a bit more point+click setup than I’d like, but hey).
Once configured and a small client script installed on the Raspberry Pi, I had reliable dynamic DNS running.
The last bit we need is DNS failover. The solution I used was the native AWS Route53 Health Check feature, where AWS adjust a DNS record based on the health of monitored endpoints.
I setup a CNAME with the wired connection as the “primary” and the wireless connection as the “secondary”. The DNS CNAME will always point to the primary/wired connection, unless it’s health check fails, in which case the CNAME will point to the secondary/wireless connection. If both fail, it fails-safe to the primary.
A small webserver (pinghttpserver) that we built earlier is used to measure connectivity – the Route53 Health Check feature unfortunately lacks support for ICMP connectivity tests hence the need to write a tiny server for checking accessibility.
This webserver runs on the Raspberry Pi, but I do a dst port NAT to it on both the wired and wireless connections. If the Pi should crash, the connection will always fail safe to the primary/wired connection since both health checks will fail at once.
There is a degree of flexibility to the Route53 health checks. You can use a CloudWatch alarm instead of the HTTP check if desired. In my case, I’m using a Lambda I wrote called “lambda-ping” (creative I know) which is a Lambda that does HTTP “pings” to remote endpoints and recording the response code, plus latency. (Annoyingly it’s not possible to do ICMP pings with Lambda either, since the container that Lambda execute inside of lack the CAP_NET_RAW kernel capability, hence the “ping-like” behaviour).
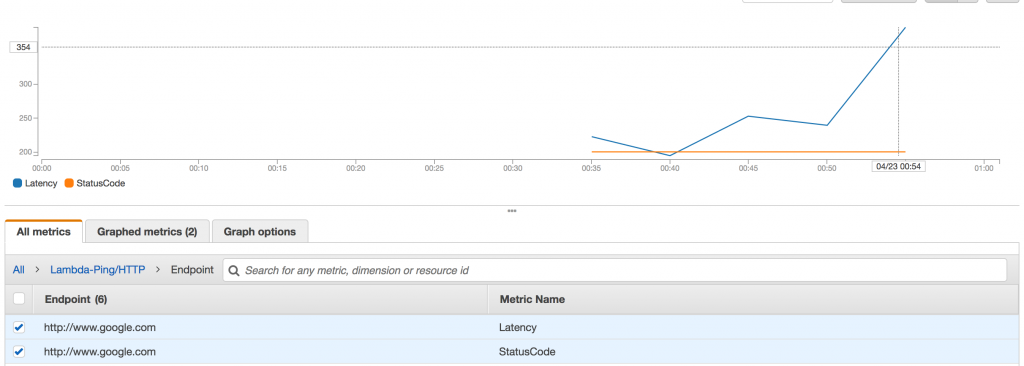
lambda-ping in action
I use this, since it gives me information for more than just my failover internet links (eg my blog, sites, etc) and acts like my Pingdom / Newrelic Synthetics alternative.
Final Result
After setting it all up and testing, I’ve installed the Raspberry Pi into the comms cabinet. I was a bit worried that all the metal casing would create a faraday cage, but it seems to be working OK (I also placed it so that the 3G modem sticks out of the cabinet surrounds).
So far so good, but if I get spotty performance or other issues I might need to consider locating the FailberryPi elsewhere where it can get clear access to the cell towers without disruption (maybe sealed ABS box on the roof?). For my use case, it doesn’t need to be ultra fast (otherwise I’d spend some $ and upgrade to 4G), but it does need to be somewhat consistent and reliable.

Installed on a shelf in the comms cabinet, along side the main Mikrotik router and the VDSL modem
So far it’s working well – the outbound failover could do with some tweaking to better handle partial failures (eg VDSL link up, but no international transit), but the failover for the inbound works extremely well.
Few remaining considerations/recommendations for anyone considering a setup like this:
- If using the one telco for both the wireless and the wired connection, you’re still at risk of a common fault taking out both services since most ISPs will share infrastructure at some level – eg the international gateway. Use a completely different provider for each service.
- Using two wired ISPs (eg Fibre with VDSL failover) is probably a bit pointless, they’re probably both going back to the same exchange or along the some conduit waiting for a single backhoe to take them both out at once.
- It’s kind of pointless if you don’t put this behind a UPS, otherwise you’ll still be offline when the power goes out. Strongly recommend having your entire comms cabinet on UPS so your wifi, routing and failover all continue to work during outages.
- If you failover, be careful about data usage. Your computers won’t know they’re on an expensive mobile connection with limited data and they’ll happily download updates, steam games, backups, etc…. One approach is using a firewall to whitelist select systems only for failover (eg IoT devices, alarm, cameras) and leaving other devices like laptops blocked to prevent too much billshock.
- Partial ISP outages are still a PITA. Eg, if routing is broken to some NZ ISPs, but international is fine, the failover checks from ap-southeast-2 won’t trigger. Additional ping scripts could help here (eg check various ISP gateways from the Pi), but that’s getting rather complex and tries to solve a problem that’s never completely fixable.
- Just buy a Raspberry Pi. Don’t waste time/effort trying to hack some ancient crap together it wastes far too much time and often falls flat. And don’t use an old laptop/desktop, there’s too much to fail on them like fans, HDDs, etc. The Pi is solid embedded electronics.
- Remember that your Pi is essentially a server attached to the public internet. Make sure you configure firewalls and automatic patching and any other hardening you deem appropriate for such a system. Lock down SSH to keys only, IP restrict, etc.